
Effective cybersecurity begins and ends with data. Since attackers can deploy their payloads in seconds, ensuring your security team isn’t waiting minutes or hours for their security operations platform to notice an attack is underway can mean the difference between an isolated threat and a widespread compromise.
While most modern cybersecurity products can detect threats quickly, what ultimately impacts their overall performance are design choices made early in the product development process, specifically how the product handles data management and processing. In this blog, we will discuss how AI-driven threat detection might work with each approach using a fictitious organization working with 50 different security products and fifty different data sources to secure their environments.
A Quick Aside on AI-Driven Threat Detection
Unlike rule-based threat detection, which looks for specific triggers of a particular data source to generate alerts, AI-driven threat detection can identify anomalies compared to expected behaviors across multiple data sources. Given this capability, a security product attempting to derive threats effectively using AI technology would require complex logic designed to normalize and enrich data across these fifty data sources.
Two Distinct Data Management Approaches
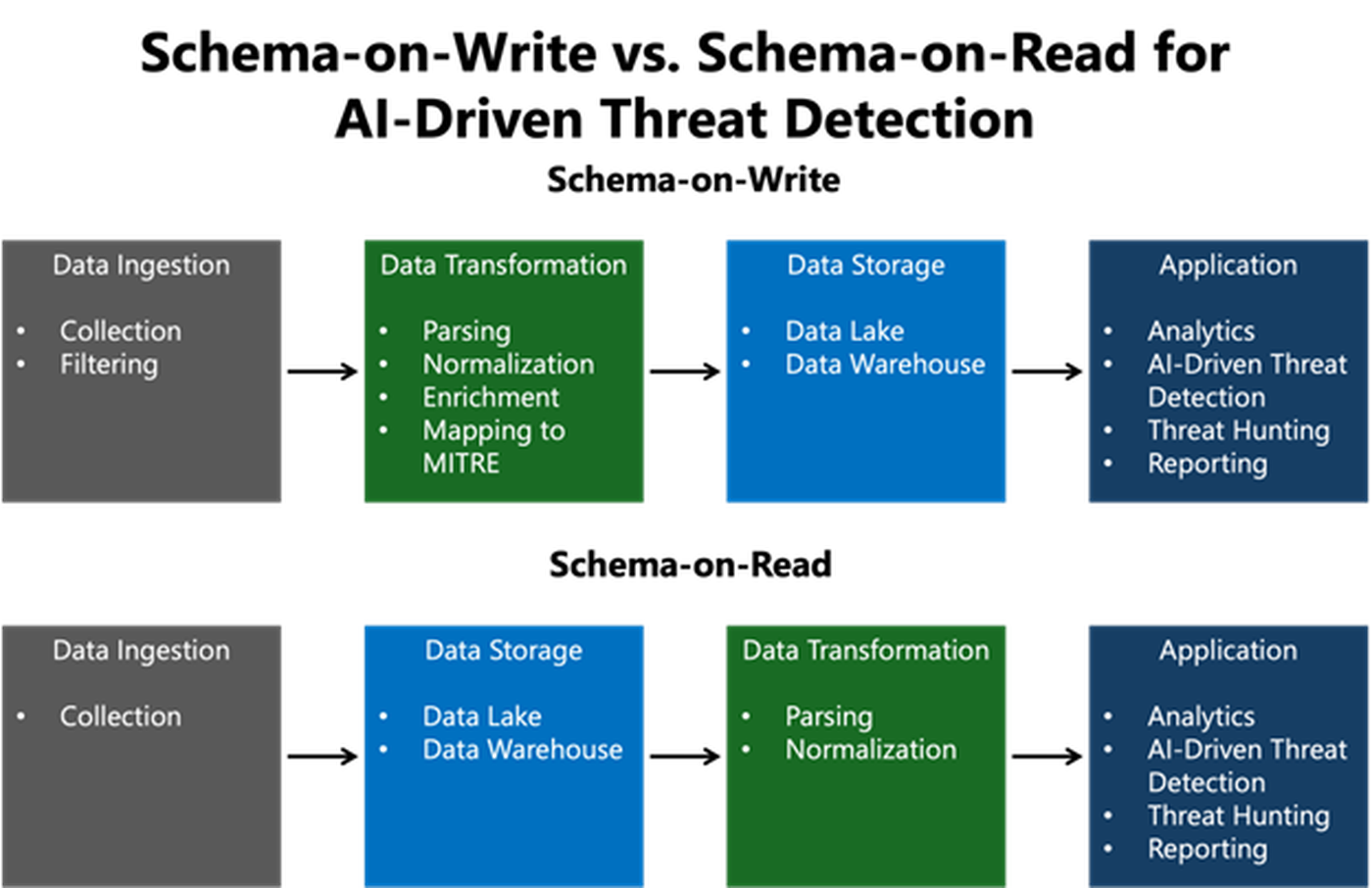
Schema-on-Read
Schema-on-Read is a data management approach where raw data ingestion occurs without applying any pre-defined schema. This approach integrates many different data sources faster as there is no need to understand the data source format upfront. Instead, the raw data is stored as-is, and any schema required for processing occurs at read time without altering the raw data. Many data engineers prefer Schema on Read since it enables them to:
Like with any technology, there are disadvantages to adopting a Schema-on-Read approach to data management:
AI-Driven Threat Detection in a Schema-on-Read World
Now that we’ve discussed the pros and cons of Schema-on-Read. Let’s consider how AI-driven threat detection might work without schema on the data. As mentioned before, AI-driven threat detection identifies anomalies compared to expected behavior. Given this requirement, an AI-based security product would require complex logic designed to normalize and enrich data “on the fly” across the stored data in different formats. Each record must be processed on the fly to avoid missing any anomaly.
It’s not hard to imagine that this approach could quickly become expensive as it will require continuous significant processing power and memory to store the processed data for different AI-driven detections temporarily. So, while the idea of ingesting raw data sounds good and might be for some non-cybersecurity use cases regarding AI-driven threat detection, the ongoing costs can quickly get out of hand. The price can become incredibly cost-prohibitive and unpredictable when data storage and AI-driven detection are from different vendors.
Schema-on-Write
Unlike Schema on Read, Schema on Write does ETL (Extract, Transform, Load), which applies some structure (schema) to data upfront, transforms, and validates the ingested data before writing to any data store. As you might expect, the benefits of Schema on Write:
To be fair, there are several limitations when it comes to Schema-on-Write approaches to data management:
AI-Driven Threat Detection in a Schema-on-Read World
With the pros and cons of Schema-on-Write identified, let’s now look at AI-driven threat detection with data schemas applied before writing to a database. We assume we work with the same organization with fifty different security products to protect their environment. Data transformations occur before loading into a database when aggregating data into a schema-on-write security platform. During this pre-processing, all data is normalized and enriched with data from other sources.
AI-driven threat detection capabilities now work with a clean data set in a standard format with context, creating a variety of baselines and identifying anomalies quickly, efficiently, and accurately. For example, detecting compromised credentials activity from an unusual physical location is easily optimized since the geographic location was added to the data during the enrichment process before writing to the database. Similarly, all IP addresses, for example, can be enriched with location information due to the normalization process, ensuring any unusual user activity is easily detected.
Which is the Right Choice for You?
When you think of a sustainable competitive advantage over attackers, a data management approach may not be the first thing that comes to mind, but it should. While there are pros and cons to each data management approach discussed above, ultimately, you must weigh the impact of a product data management strategy on your goals before adopting it, as this has enormous implications on the cost, your ability for threat hunting through effective search, and your ability to develop your own AI-driven or even manual rules for threat detections.
Stellar Cyber is built on a Schema-on-Write data management approach, providing our customers with effective and accurate AI-driven threat detection results, fast threat hunting, and flexible development capability for your threat analysis. Additionally, when organizations use our platform’s Bring Your Own Data Lake (BYODL) capability, they can see significant cost savings by storing only the results in their data lake or their existing SIEM. To learn more about how Stellar Cyber works to optimize our engagement with your data, contact us today to set up a personalized consultation.
Guest blog courtesy of Stellar Cyber. Read more Stellar Cyber guest blogs and news here. Regularly contributed guest blogs are part of MSSP Alert’s sponsorship program.



