
Detecting and interrupting phishing incidents is hardly the most exciting thing in cybersecurity, but that’s exactly why you should automate it for your clients. In this article, we will show you step-by-step how you can design a phishing playbook for your automation platform and explore how automating use-cases like phishing can help you deliver a more profitable, scalable managed service.
Why are Playbooks for Phishing Incidents Important for MSSPs?
In a recent study of 75,000 real-world incidents, we found that phishing was the third-most-common adversary technique, representing 16% of all incidents. Because phishing occurs so frequently, it can become a huge time-waster for MSSPs, cutting into profits by tying up your staff and increasing the risk of burnout with monotonous tasks. It’s cheap for cybercriminals to launch massive phishing campaigns, so without tools that can group related incidents into larger cases, you can waste even more time handling each malicious email separately.
There are no signs of phishing attacks slowing down any time soon. Since 2019, the number of phishing attacks has increased by more than 150% yearly. In 2022, the Anti-Phishing Working Group (APWG) logged ~4.7 million phishing attacks. In a survey conducted by Osterman Research, it was found that IT and Security teams take an average of 27.5 minutes to handle a single phishing email and the estimated cost of discovering and mitigating a single phishing email is $31.32.
If you are managing security for a large customer base, you can see how this one incident type could account for a huge amount of wasted time, while posing a significant security risk to your clients. The good news is that because most phishing attacks are unsophisticated, they can be easily combatted with automation. So, now let’s look at how you can plan and wireframe a playbook for phishing incidents.
How to Design a Phishing Playbook
Our expertise is in SOAR, so our recommendations are based on the automation and orchestration functions of that technology, but the principles — and many of the specifics — should translate to different automation platforms.
We will use the example of ingesting suspicious emails through Office 365, with supporting tools including CrowdStrike Falcon and Microsoft Entra ID (formerly known as Active Directory). The combination of these tools and a few others will deliver a complete, end-to-end incident response workflow that will eliminate manual triage and data-gathering, help your team — and your clients’ teams — make more accurate decisions, and automate containment and recovery.
Preparation
Your playbook will need to act across several tools, so start by identifying the integration commands you have available in those tools. Then, to narrow down what commands you’re using, list out the artifacts the playbook needs to process. This can be done by looking at the raw data from an Office 365 alert to identify what artifacts it contains. Next, identify what commands can take those artifacts as inputs. Once you have that list, you can categorize them into three groups: enrichment, containment, and recovery.
Wireframing
The next stage of building a playbook is wireframing, which is hugely valuable as a way to validate the logic of the workflow and fix any issues alongside other stakeholders in your organization before you spend the time to build and deploy the playbook.
In our experience, there are four key stages to playbooks: triage, enrichment, containment, and recovery:
In the triage phase, set up your playbook to determine the severity of the alert by checking the authenticity of the email. Each authentication check can contribute a value to the overall risk score. The calculation could look something like this, with any alert with more than 70 points being deemed as critical:
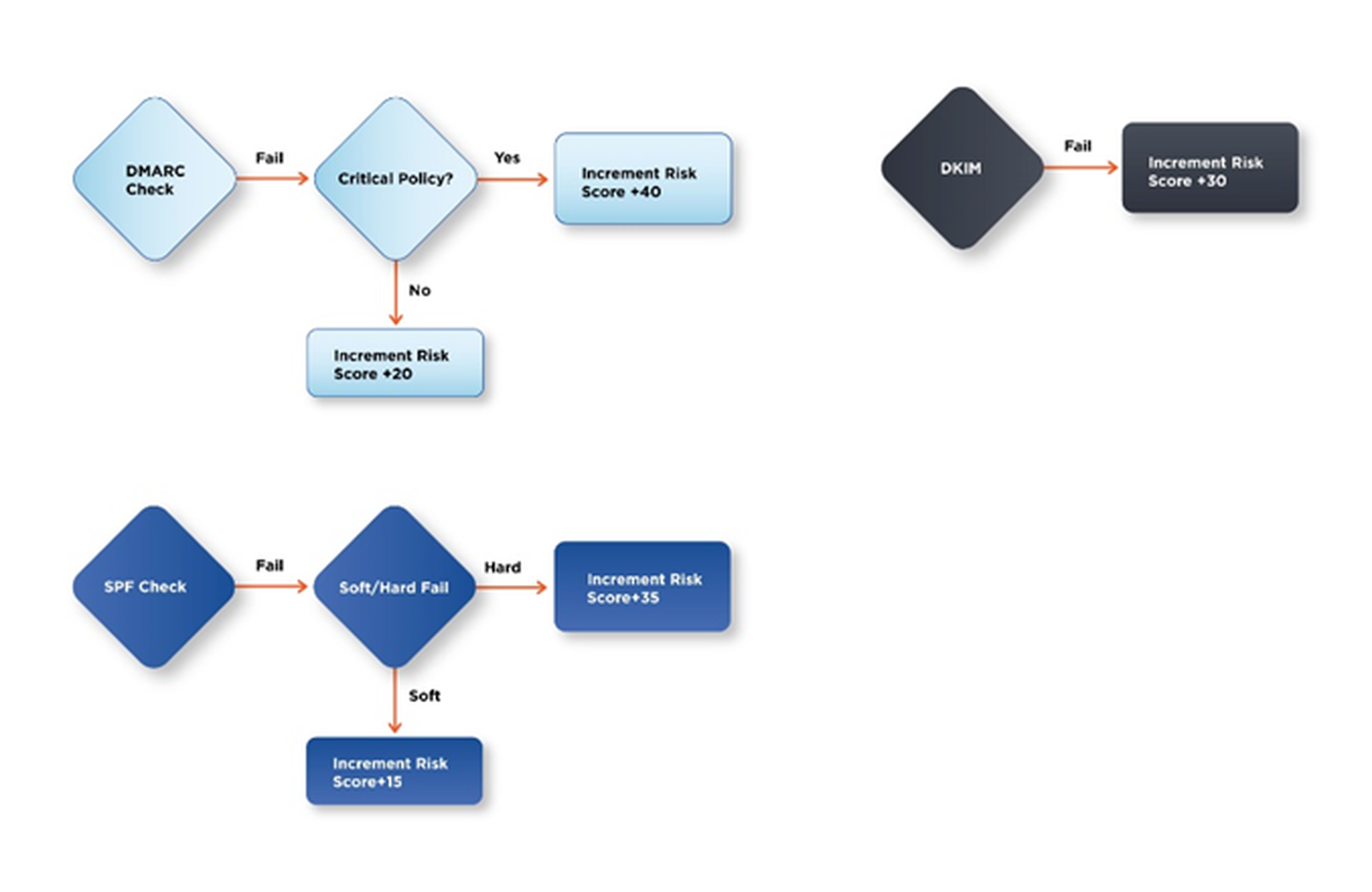
Because you’ve already identified the artifacts in the suspicious email alerts and the integration commands that they apply to, wireframing the enrichment stage should be straightforward. Break the workflow into streams, one for each artifact. Then connect the relevant commands in a logical sequence. For example, the stream for the “recipient email” artifact could look like this:
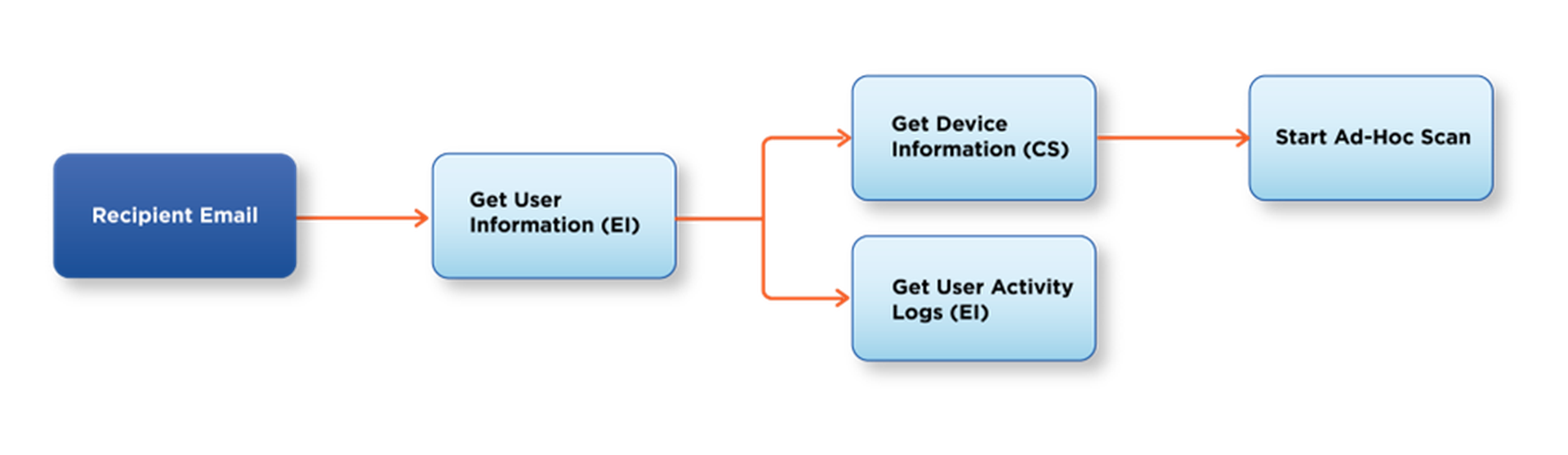
In the above example, we want to get additional details on the recipient from our IAM tool, Entra ID. This will include their enrolled groups and devices. Once we have their username, we can collect their activity logs for a complete picture on this user. At the same time, we can collect device information from CrowdStrike and start an ad-hoc scan to review later.
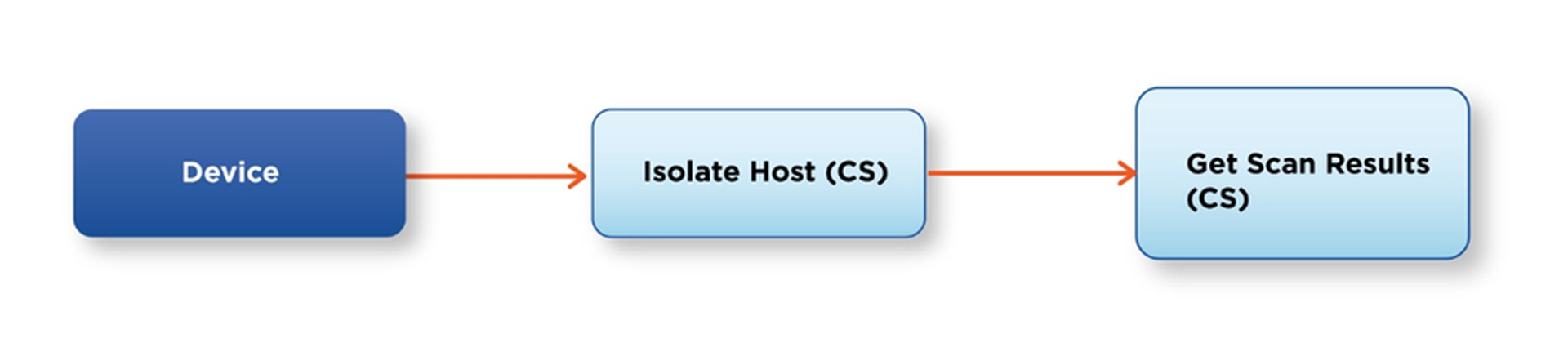
After the enrichment stage, the playbook should present a decision point to the user: continue to containment or close the incident. If the user continues to containment, the playbook should now present potential actions for them to take for each artifact. For example, the “device” containment stream might leverage CrowdStrike and look like this:
In the recovery stage, the playbook should ensure that all assets are returned to their usual functions. Continuing with the example of the “device” stream, once suspicious connections and processes are terminated, and vulnerabilities have been patched, you can bring the device back online with CrowdStrike.
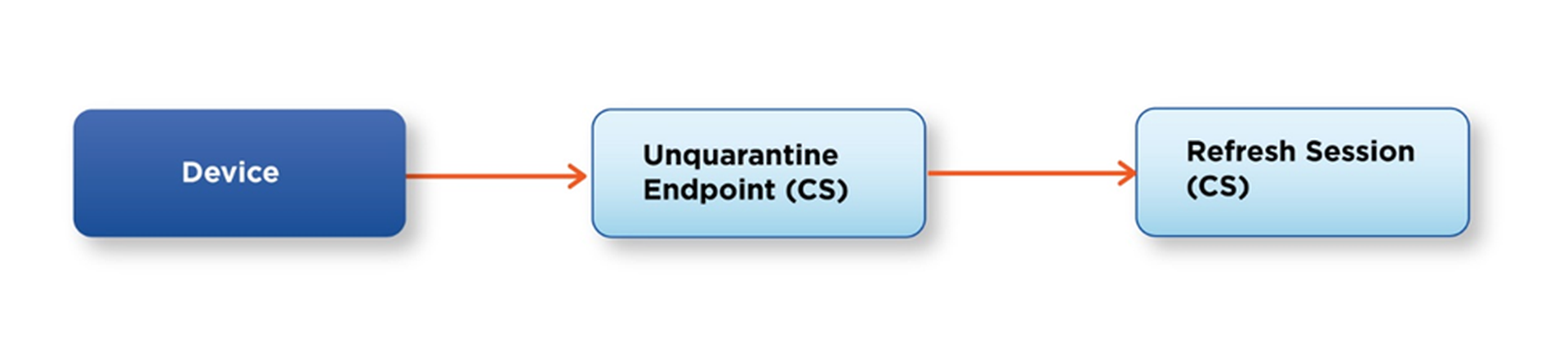
Now that you’ve wireframed the recovery stage, you’ve created the foundation for a playbook that can automate the vast majority of tasks associated with phishing incidents, leaving only the key decisions to your human users. When combined with other automated capabilities, such as grouping together related phishing incidents into cases, you can save a massive amount of time and resources through automating phishing response for your clients. This type of playbook can be applied across your customer base with minimal customization, representing significant scalable value.
Of course, you still need to test and publish the playbook, so perhaps we’ll cover that in a future article.
Guest blog courtesy of D3 Security. Read more D3 Security guest blogs and news here. Regularly contributed guest blogs are part of MSSP Alert’s sponsorship program.



